前言
最近想自己训练个模型在和别人语音的时候用,于是了解到了RVC这个项目
Retrieval-based-Voice-Conversion-WebUI
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
它可以实现人声模型的训练和实时推理
数据集准备
Q10:需要多少训练集时长
推荐10min至50min
保证音质高底噪低的情况下,如果有个人特色的音色统一,则多多益善
高水平的训练集(精简+音色有特色),5min至10min也是ok的,仓库作者本人就经常这么玩
也有人拿1min至2min的数据来训练并且训练成功的,但是成功经验是其他人不可复现的,不太具备参考价值。这要求训练集音色特色非常明显(比如说高频气声较明显的萝莉少女音),且音质高;
1min以下时长数据目前没见有人尝试(成功)过。不建议进行这种鬼畜行为。
根据官方说法,我们大概需要准备15分钟左右的干声
我训练的是普拉娜的模型,音频数据主要来自游戏解包还有阿罗普拉频道,关于游戏解包数据我推荐使用这个项目:
Blue Archive Asset Downloader
https://github.com/ZM-Kimu/Blue-Archive-Asset-Downloader
游戏解包音频可以直接用,视频提取的音轨还要做处理
一般音频处理
首先打开webui,在RVC的根目录下打开go-web.bat
转到伴奏人声分离&去混响&去回声选项卡
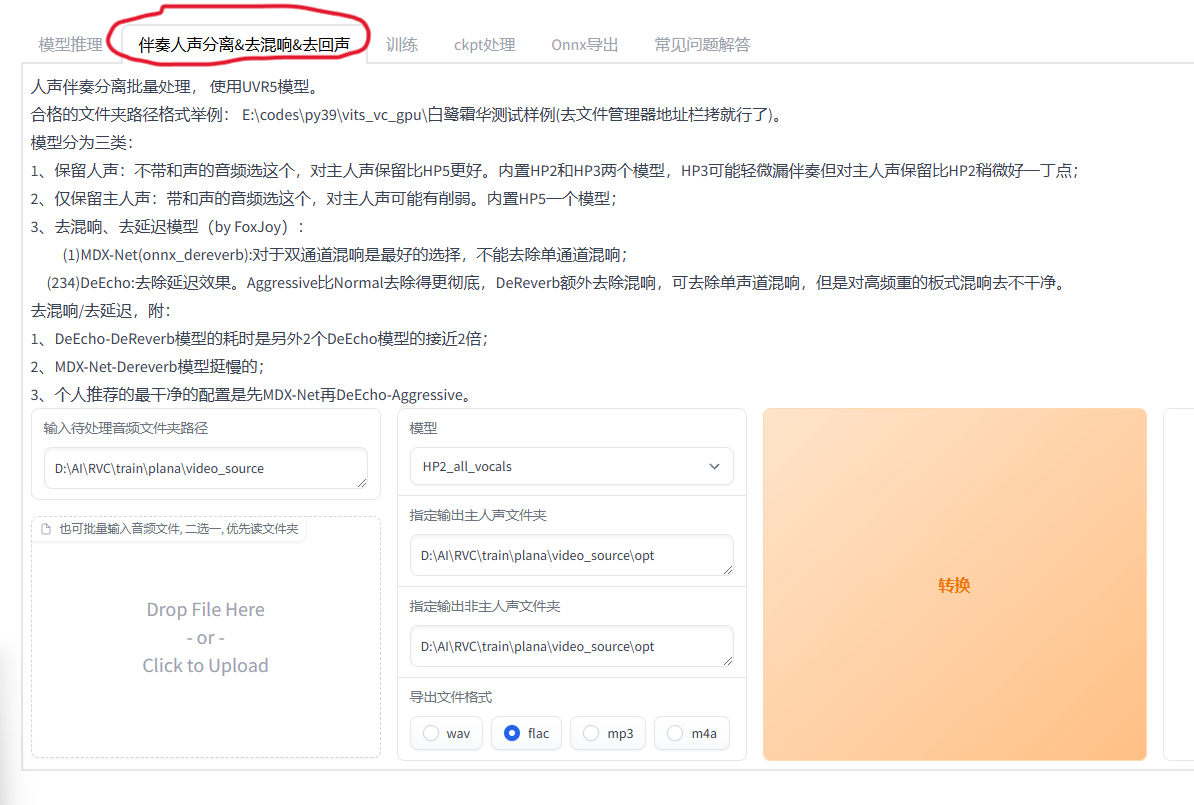
把要处理的文件放在一个文件夹内,并在输入待处理音频文件夹路径里输入目录的路径,导出格式建议选wav,因为之后训练要用wav格式的文件
模型的选取可以参考作者的说明,我的建议是
- 如果只是单纯的一般交谈声和bgm分离,用HP2或HP3比较适合
- 如果是歌曲分离干声和伴奏可以考虑先用MDX-Net去混响再用DeEcho去延迟
转换后的文件默认再RVC目录下的opt目录内
将所有的训练音频整合到同一个文件夹内
模型训练
Step 1&2
首先是基本的设置
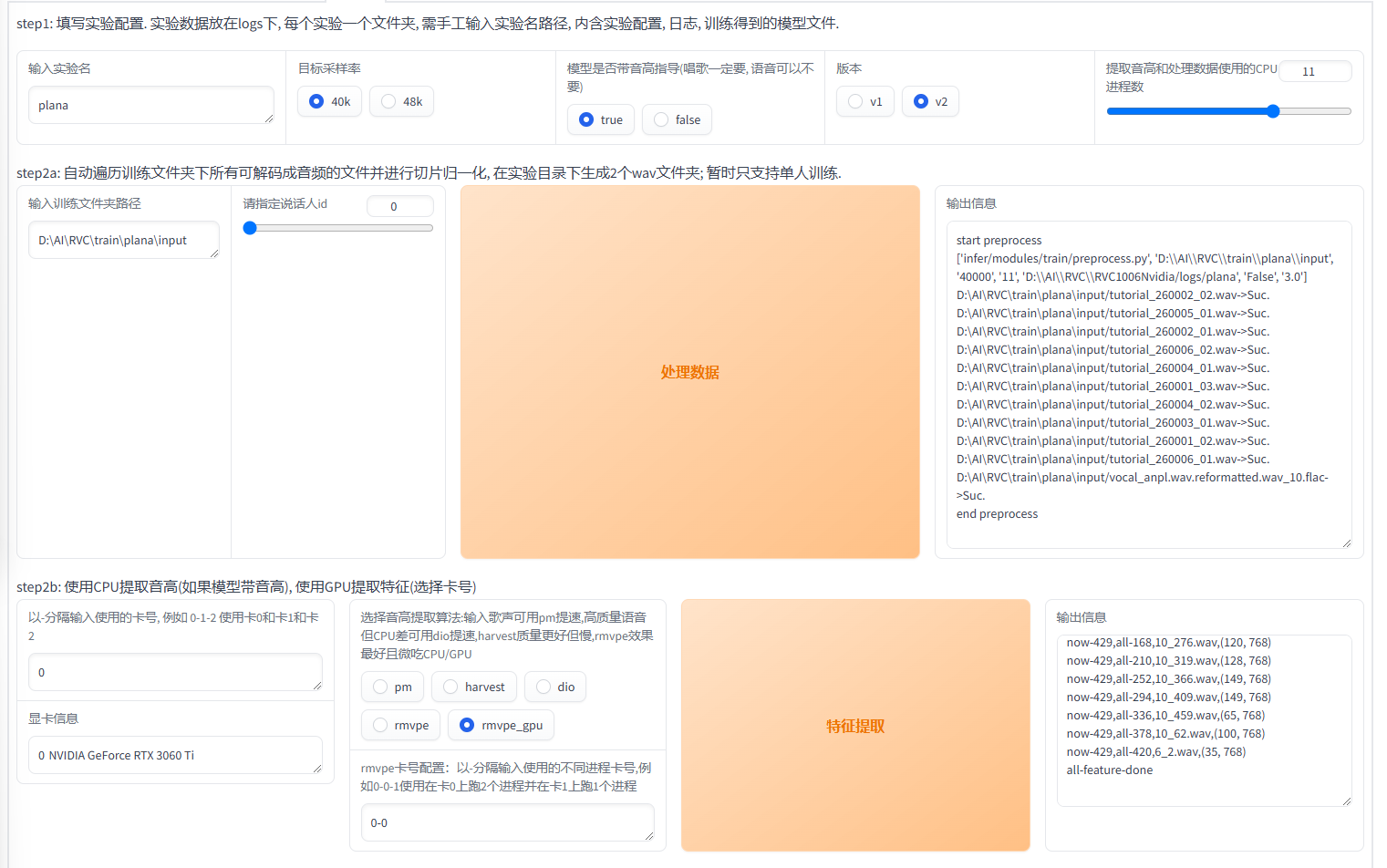
- 实验名:模型的名称
- 目标采样率:与训练的音频相同
- 版本选v2
- 训练文件夹路径:填入刚才存放训练音频的文件夹路径
其余全部默认即可
Step 3
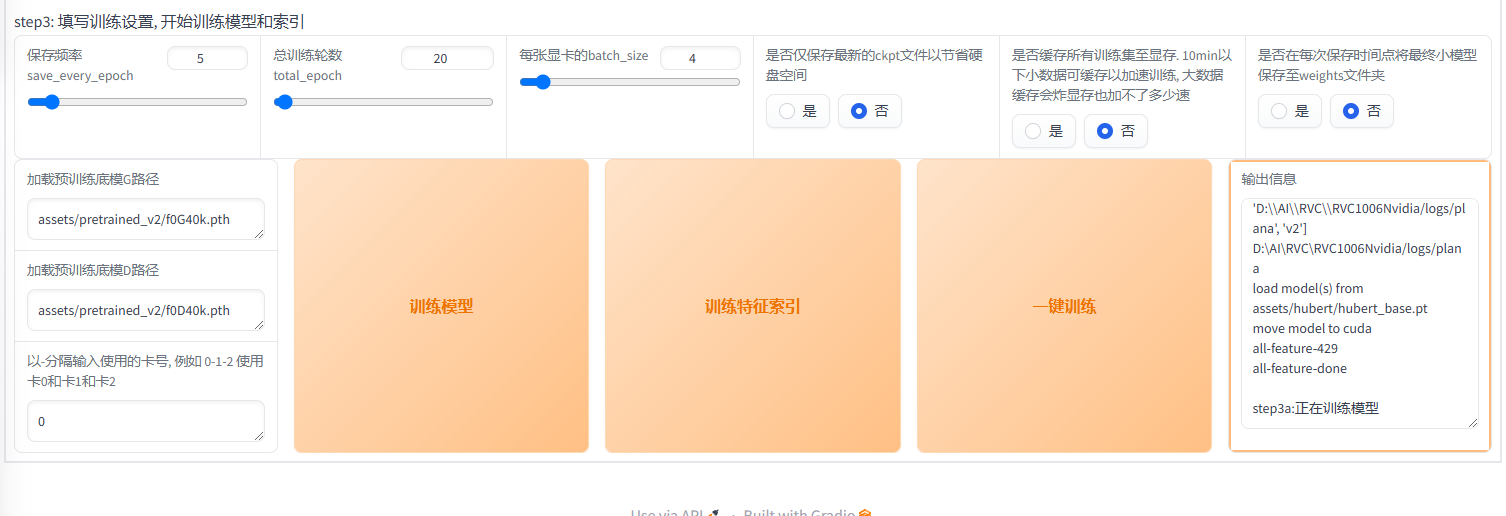
训练设置部分:
一般保持默认即可
epoch在20附近比较合适
一键训练
- 点击一键训练可以直接一次跑完step 1 & 2 & 3,等待输出以下内容即可
1 | step3a:正在训练模型 |
- 如果不使用一键训练,依此进行
处理数据→特征提取→训练模型→训练特征提取是一样的
更多问题可以参考官方wiki中的的常见问题解答
训练完成后的文件
-
训练完成后,在
/assets/weights目录下将会生成与实验名称同名的pth文件

-
在
logs/<实验名称>会生成一个added开头的index文件,这是模型的索引

⚠️注意,logs/<实验名称>下的pth文件并不适用于推理!!!
模型使用
1.WebUI
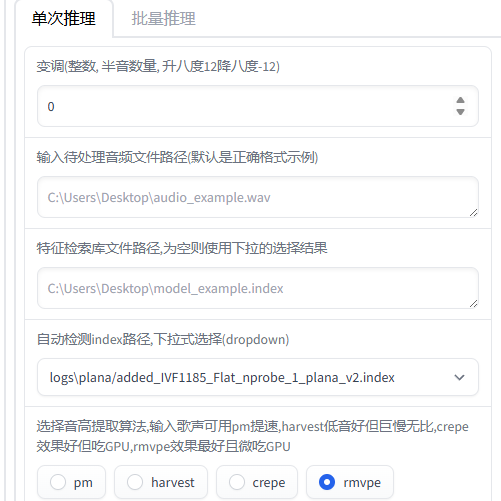
在模型推理选项卡中刷新音色就可以看到刚刚训练好的模型,选择音色
- 在
自动检测index路径,下拉式选择(dropdown)中选择刚才的index文件 输入待处理音频文件路径中输入希望进行变声的音频文件
✨ 这里的输入音频必须是干声,否则结果将会极其鬼畜!!!- 调整参数,然后点击转换即可
生成实例
翻唱
Feel my soul
寺泽百花
- 合成:
- 干声:
交谈
2.实时语音转换
使用RVC目录下的go-realtime-gui.bat即可打开实时语音转换
安装虚拟声卡
首先我们需要安装虚拟声卡,我用的是voicemeeter
Voicemeeter
https://voicemeeter.com
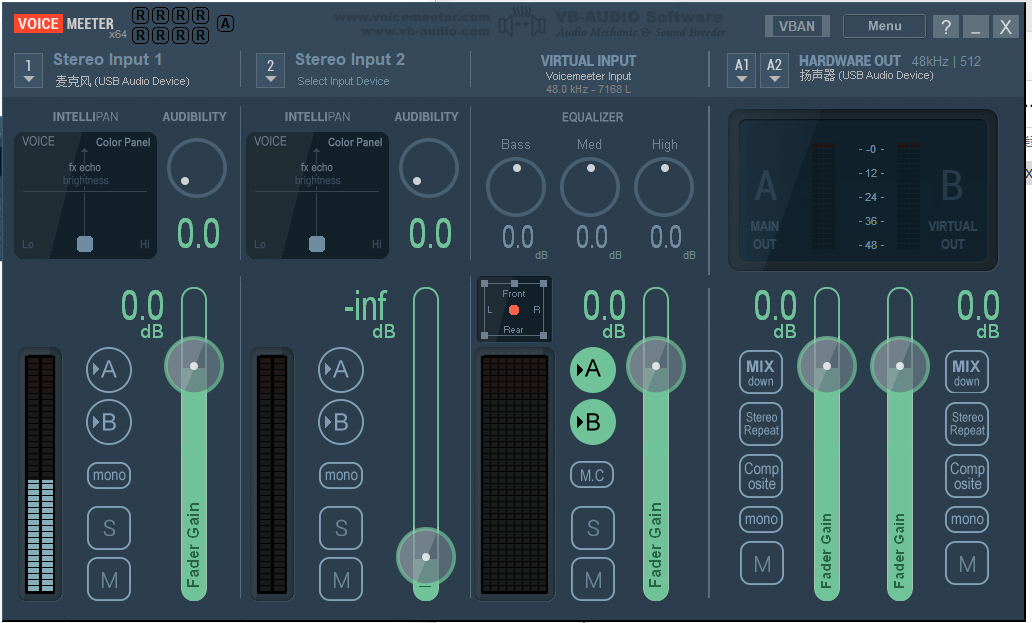
打开后:
- stereo input 1 & 2 表示第一、二个物理输入设备
- VIRTUALINPUT 表示虚拟输入,go-realtime-gui就要在这里输入虚拟声卡
- 这里的A和B分别表示输出到物理输出设备和虚拟输出设备,点亮就是开启这条输出通道
- 换句话说,打开A就会输出到耳机和音响,打开B就会输出到系统内的软件
- 最后HARDWARE OUT可以设置要输出声音的物理输出设备(例如音响和耳机)
在go-realtime-gui内
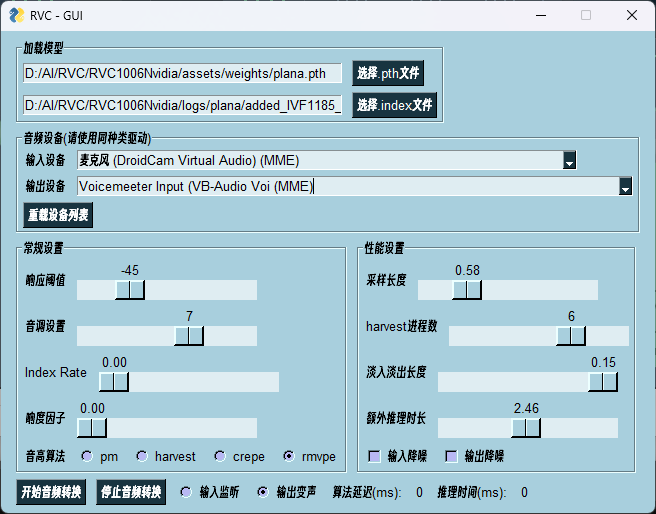
- 输入设备设置为你的麦克风
- 输出设备(输入声卡)直接选
Voicemeeter Input(VB-Audio Voi MME)即可打开实时语音转换
其他设置部分:
- 音调如果是男声变女生尽量拉高,反之拉低
- 建议打开降噪
点击开始音频转换即可看到Voicemeeter里面虚拟通道有输入了
如何在软件内使用
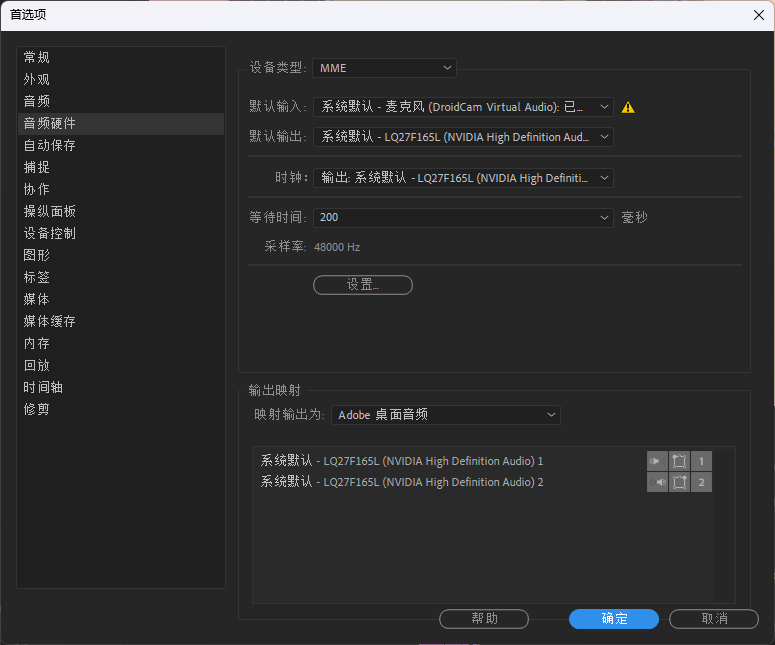
这里以Pr为例,在音频硬件首选项中选择输入音频设备为Voicemeeter Out Bn
n为正整数
⚠️ 不要选择带A的,那些是物理输出
至此就全部完成啦 ヾ(≧▽≦*)o

